Separate Methoden für HTTP-Anfragen
RGeschrieben vonRiku Virtanen Vor über einer Woche aktualisiertTable of contentsAndere Techniken für HTTP-Anfragen
Standardisierte REST-APIs, SOAP-Dienste und GraphQL-APIs sind nur ein Teil des Spektrums an HTTP-Anfragen. Dieses Modul umfasst die anderen Arten häufig vorkommender HTTP-Anfragen, die einige spezifische Merkmale aufweisen, die man sich merken sollte. Außerdem können einige dieser Themen manchmal in Verbindung mit den zuvor behandelten HTTP-Anfragepraktiken verwendet werden.
Übertragen von Dateien über HTTP-Anfragen
Zuvor haben wir die Datenübertragung über HTTP in JSON, XML oder anderen strukturierten Typen behandelt, aber das Senden oder Abrufen ganzer Dateien oder beliebiger Nutzdaten als Byte-Arrays ist ebenfalls möglich. Daher müssen die Dateien in der HTTP-Nutzdaten als Byte-Arrays verarbeitet werden, was mit drei verschiedenen Frends-Aufgaben möglich ist.

Diese Tasks haben ihre eigenen Anwendungsfälle und ihre Namen sollten angeben, wofür sie verwendet werden sollen. Nur die Nutzlast, die Antwort oder die eingeschränkte Sammlung von HTTP-Methoden unterscheiden sich vonHttpRequestoderRestRequestAufgaben. SchließlichHttpRequestUndRestRequestTasks verarbeiten die Nutzdaten letztendlich als Byte-Arrays auf der Ebene des Übertragungsprotokolls, erleichtern aber die Entwicklung, da sie die Nutzdaten als strukturierte Zeichenfolgenformate für das menschliche Auge bereitstellen. Dies bedeutet, dass jeder HTTP-Endpunkt, der mit den zuvor erwähnten Tasks verwendet werden kann, mitHttpRequestBytes, HttpSendBytesoderHttpSendAndReceiveBytesAufgaben, solange die Nutzdaten je nach Anwendungsfall von Zeichenfolgen in Byte-Arrays oder von Byte-Arrays in Zeichenfolgen konvertiert werden.
HttpRequestByteszum Abrufen von Bytes als HTTP-Antwort.
HttpSendByteszum Senden von Bytes als Teil der HTTP-Anfrage.
HttpSendAndReceiveByteszum Senden und Empfangen von Bytes als Teil der HTTP-Anfrage und -Antwort.
| HttpRequestBytes | HttpSendBytes | HttpSendAndReceiveBytes |
HTTP-Methoden |
|
|
|
Nutzlast anfordern | Zeichenfolge | Byte-Array | Byte-Array |
Antworttext | Byte-Array | Zeichenfolge | Byte-Array |
So fordern Sie Bytes über HTTP an
Man kann Bytes anfordern, indem man denHttpRequestBytesAufgabe und Konfigurieren der HTTP-Anforderung wie jede andere, wobei erwartet wird, dass der Server den Inhalt als Bytes zurückgibt. Die Aufgabe gibt auch die Eigenschaft ContentType zurück, die angibt, welcher Dateityp empfangen wurde, sodass die Datei später im Prozess ordnungsgemäß verarbeitet werden kann. Auf die Datei als Byte-Array selbst wird mit der Notation #result.BodyBytes verwiesen.
So senden Sie Bytes über HTTP
Das Senden von Bytes über HTTP erfordert die Verwendung vonHttpSendBytesAufgabe, die die Nutzlast als Byte-Array übernimmt. Außerdem ist es eine gute Praxis, erforderliche HTTP-Header wie Content-Type: octet-stream zu verwenden. Normalerweise wird in der Dokumentation des HTTP-Endpunkts erläutert, welche HTTP-Header verwendet werden sollten, um zusätzliche Informationen anzugeben, beispielsweise den Zweck oder den Namen der übertragenen Datei.
So senden und empfangen Sie Bytes über HTTP
Um das Senden und Empfangen von Bytes zu kombinieren,HttpSendAndReceiveBytesEs muss eine Aufgabe verwendet werden, die einfach die Funktionalität der oben dargestellten Aufgaben kombiniert.
Der folgende Prozess demonstriert die gängigen Anwendungsfälle des Transports von Byte-Arrays über HTTP und wie diese in eine Datei geschrieben oder eine Datei als Byte-Array gelesen werden.

URL-Kodierung in HTTP-Anfragen
Manchmal erfordert ein HTTP-Endpunkt, dass die übertragenen Daten in der URL der Anforderung enthalten sind. Das bedeutet, dass die Daten ASCII-kompatibel sein müssen, ohne beispielsweise Leerzeichen und bestimmte Satzzeichen. Dadurch entstand die Notwendigkeit einer gemeinsamen Kodierung dieser Sonderzeichen, damit die Daten in der URL erscheinen können. Daher kommt auch der Name URL-Kodierung.
Beispielsweise gibt es im URL-Kodierungsraum '+', das Pluszeichen '%2B', das Gleichheitszeichen '%3D', das Fragezeichen '%3F' usw. Wenn wir beispielsweise die Zeichenfolge 'Dies + dies = dies! Wirklich?' als URL kodieren würden, würden wir 'Dies+%2B+dies+%3D+dies!+wirklich%3F' erhalten.
Ursprünglich stellte die URL-Kodierung sicher, dass alle Arten von Zeichen in der URL einer HTTP-Anfrage übertragen werden konnten, aber heutzutage erfordern einige Endpunkte auch eine URL-Kodierung in der Nutzlast. Per Definition sind die Abfrageparameter in der URL einer HTTP-Anfrage URL-kodiert, was zu folgendem Format führt: ?key1=UrlEncoded(value1)&key2=UrlEncoded(value2). Darüber hinaus verwenden HTML-Formulare die URL-Kodierung für die Formularübermittlung, aber im Kontext von Integrationen besteht der Hauptanwendungsfall der URL-Kodierung darin, die Nutzlast oder Daten in URLs zu formatieren. Der typische HTTP-Header für URL-kodierte Daten ist Content-Type:application/x-www-form-urlencoded.
Als Beispiel könnten wir eine API für einen Dienst haben, der SMS-Nachrichten entsprechend den HTTP-Nutzdaten sendet, die Schlüsselwertpaare sind, die mit URL-Kodierung formatiert und durch & getrennt sind. Das folgende Bild zeigt, wie dieser imaginäre API-Aufruf aussehen würde, vorausgesetzt, die referenzierten Daten sind bereits URL-kodiert.

Zusätzlich könnten wir sicherstellen, dass die referenzierten Werte des Triggers tatsächlich URL-codiert sind. Beispielsweise könnten wir den Message-Wert mit einem C#-Ausdruck in den Handlebars URL-codieren: #{{WebUtility.UrlEncode(#trigger.data.Message)}}.
Die Notwendigkeit der URL-Kodierung wird normalerweise in der HTTP-Endpunkt- oder API-Dokumentation deutlich angegeben.
Bilden mehrteiliger HTTP-Anfragen
Eine mehrteilige HTTP-Anforderung ermöglicht die Übertragung mehrerer Dateien oder Datensätze in einer einzigen HTTP-Anforderung. Diese Vorgehensweise wird verwendet, wenn der Anwendungsfall das Senden einer Datei und zusätzlicher Metadaten erfordert. Die Nutzlast der mehrteiligen HTTP-Anforderung wird in Teile aufgeteilt, die durch eine in einem HTTP-Header definierte Begrenzungszeichenfolge getrennt sind. Außerdem haben die Teile ihre eigenen beschreibenden Header. Das folgende Bild zeigt ein Beispiel für eine mehrteilige Anforderung.
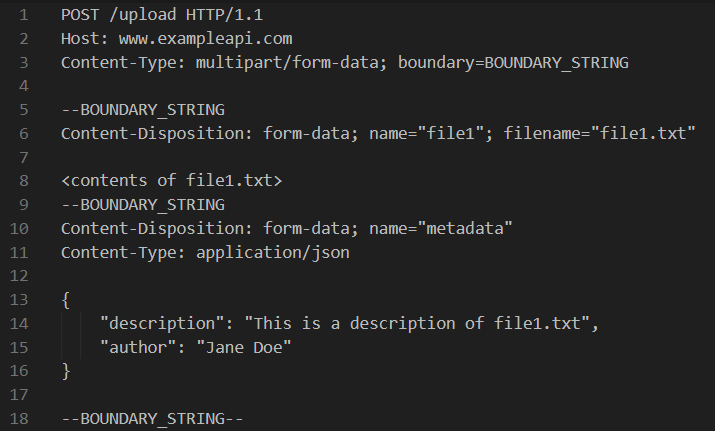
In diesem Beispiel wäre die URLwww.api.example.com/uploadund ein HTTP-Header Content-Type: multipart/form-data; boundation=BOUNDARY_STRING. Der Body besteht aus zwei Teilen, die mit --BOUNDARY_STRING beginnen, und dem gesamten Body, der mit --BOUNDARY_STRING-- endet. Im ersten Teil befindet sich eine Datei und im zweiten Teil gibt es JSON-formatierte Metadaten.
Diese Art von HTTP-Anforderung kann mit Frends auf zwei Arten erfolgen: durch die Verwendung eines bestimmtenFormular absenden Formular sendenAufgabe bzw. Bildung der HTTP-Anfragen mitHttpRequestoderRestRequestAufgaben.
JSON-Web-Token in HTTP
Eine gängige Praxis bei HTTP-Anfragen ist die Verwendung von JSON Web Tokens (JWT), die eine sicherere Datenübertragung zwischen Parteien ermöglichen, da die Daten mit offenen und standardisiertenVerfahren. JWTs bestehen aus Header, Payload und Signatur, die Base64-URL-codiert und mit einem Punkt verbunden sind, um Zeichenfolgen wie im folgenden Beispiel zu bilden.
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyLCJwYXlsb2FkIjp7InByb3BlcnR5MSI6InByb3BlcnR5MWRhdGEiLCJwcm9wZXJ0eTIiOiJwcm9wZXJ0eTJkYXRhIn19.jxpj1D36Mruq9mgHgcjpHbyVVtfLAwJ5d8IE9UWhJH0
In diesem Beispiel enthält der Header eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9 Informationen zum Hashing-Algorithmus und zum Typ des Tokens. Wenn dieser Header wieder in die JSON-Darstellung konvertiert wird, erhalten wir das folgende Objekt:
{
"alg": "HS256",
"typ": "JWT"
}
Der zweite Teil des JWT, die Nutzlast eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyLCJwYXlsb2FkIjp7InByb3BlcnR5MSI6InByb3BlcnR5MWRhdGEiLCJwcm9wZXJ0eTIiOiJwcm9wZXJ0eTJkYXRhIn19, enthält die Ansprüche, die standardisierte Aussagen über den Verbraucher mit zusätzlichen Informationen sind. Unsere Beispielnutzlast würde in das folgende JSON-Objekt konvertiert:
{
"sub": "1234567890",
"Name": "John Doe",
"iat": 1516239022,
"Nutzlast": {
"Eigenschaft1": "Eigenschaft1Daten",
"Eigenschaft2": "Eigenschaft2Daten"
}
}
Der letzte Teil des JWT, die Signatur, wird mit dem im Header angegebenen Algorithmus berechnet, in diesem Fall HS256. Die Berechnung hasht den Header und die Nutzlast mit einem möglichen Geheimnis: HMACSHA256(base64UrlEncode(header)+"."+base64UrlEncode(payload),secret). Diese Berechnung würde schließlich die Signatur von jxpj1D36Mruq9mgHgcjpHbyVVtfLAwJ5d8IE9UWhJH0 erzeugen. Sie können sich dieses spezielle Beispiel unter ansehenjwt.io.
Es stehen mehrere Hashing-Algorithmen zur Verfügung und sogar Algorithmen, die asymmetrische öffentlich-private Kryptografie wie RS256 verwenden.
JWTs werden häufig als Bearer-Token von OAuth-Flows verwendet, da sie signierte Informationen wie die Ansprüche über den Ressourcenverbraucher bereitstellen können. Manchmal kann die HTTP-Nutzlast selbst ein JWT sein, das validiert und analysiert werden muss, um die Daten in einem Integrationsanwendungsfall verwenden zu können.
Frends bietet eine Reihe von Aufgaben zum Validieren, Parsen und Erstellen von JWTs als Teil von Anwendungsfällen zur HTTP-Integration.

Diese Aufgaben sollten in Verbindung mit den HTTP-Aufgaben verwendet werden, um JWTs zu übertragen oder zu verarbeiten.
HTTP-Nutzdaten oder Autorisierungsinformationen von HTTP-Anfragen können signiert werden, um sicherzustellen, dass die übertragenen Daten selbst nicht manipuliert wurden.
Der nächste Artikel istEinführung in die Authentifizierung in HTTP-Integrationen
Verwandte ArtikelHTTP-TriggerEinführung in HTTP-TriggerEinführung in die HTTP-BinärantwortEinführung in Integrationen mit HTTPEinführung in die Authentifizierung in HTTP-Integrationen